
Dostałem ostatnio prośbę o pomoc przy Pythonie. Wczytywane dane z pliku tekstowego źle się wyświetlały.
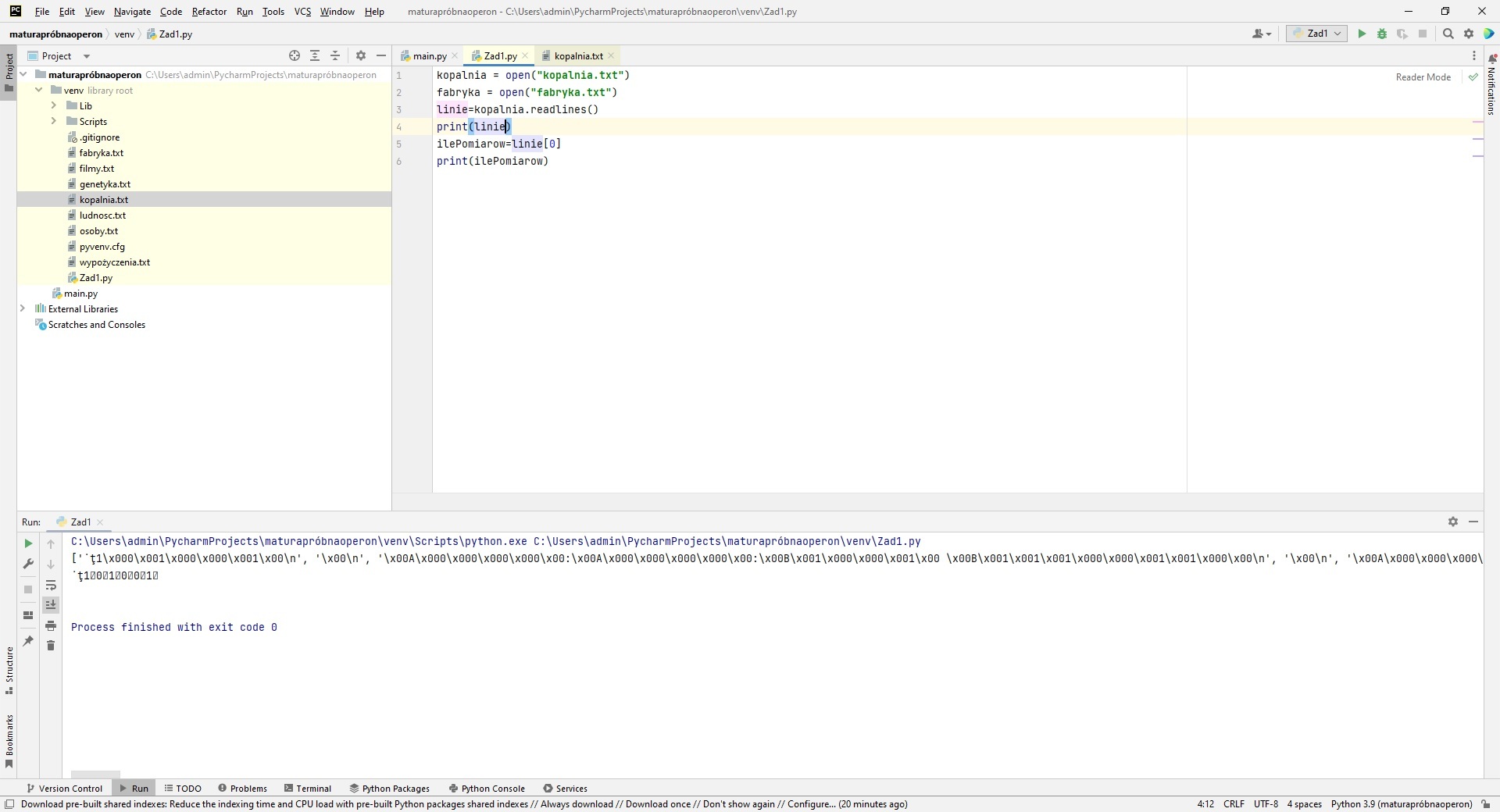
Chcę pomóc, ale przede wszystkim chcę dojść do źródła problemu. Więc rozwiązanie będzie pod koniec tego artykułu, a w środku, droga dojścia do prawdy, czyli do danych źródłowych, i co wynika z używania Notatnika… zacznijmy zatem.
Na początek proszę o plik źródłowy, który osoba, która prosi o pomoc, ma z Operonu. Ponieważ po południu akurat korzystam tylko z telefonu komórkowego, więc tam mam jakiś prosty notatnik, w nim widzę dziwny początek pliku.

Więc dopytuję się, czy patrzyła na ten plik, a z powrotem otrzymuję screen z Notatnika Windowsowego:

A więc szybko zapisuję sobie plik na dysku, i wczytuję do Kate – taki lepszy notatnik dla Linuksa, bo oczywiście ja używam Linuksa, a nie Windows. Ale nie o tym. Efekt w Kate – podobny jak w Notatniku.
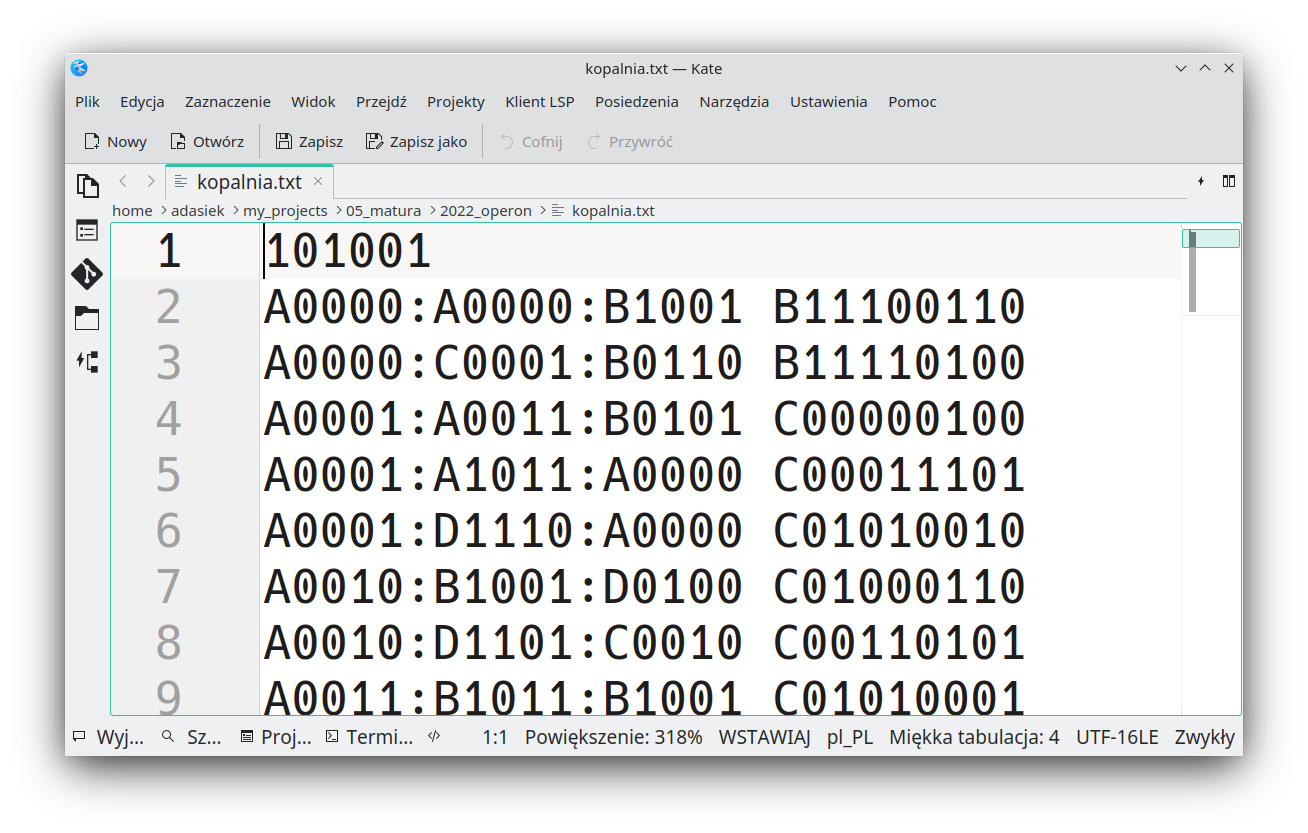
Czas więc przypatrzeć się naszemu plikowu – czy ktoś pamięta stare czasy, kiedy istniał Norton Commander? W Linuksie istnieje nadal w postaci Midnight Commander, a dodatkowo mamy projekt CRT Monitor… Widok jest wręcz rewelacyjny, jeśli ktoś pamięta bursztynowe monitory.

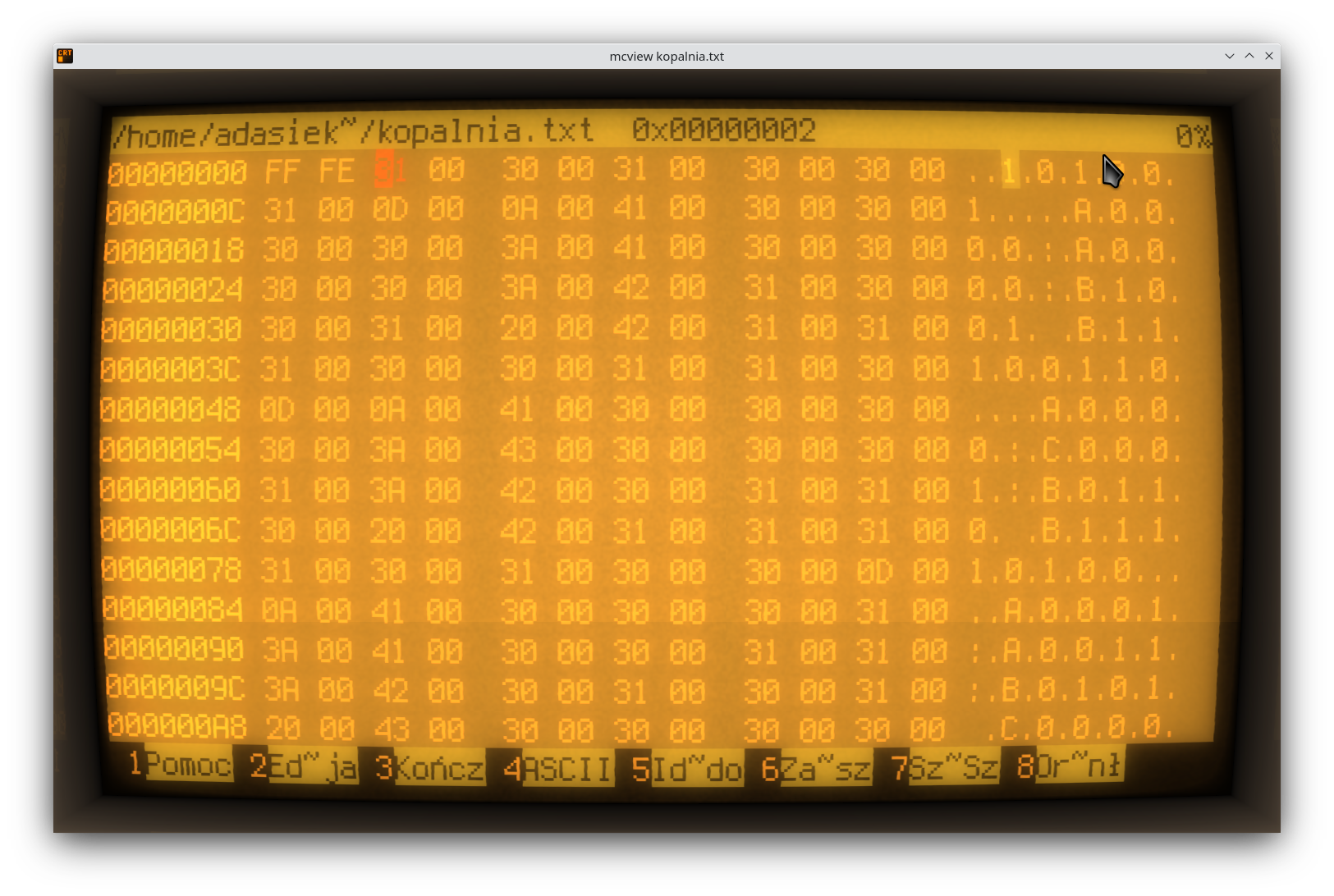
A teraz czas na dokładny widok, w trybie HEX (czyli szesnastkowym). Kiedyś, dawno temu – znajomość trybu szesnastkowego była ważna, jak widać, przydaje się i dziś…
Teraz dodatkowo Sprawdźmy plik w graficznym edytorze szesnastkowym – jest to OpenSource z wersjami dla Linux, macOS, Windows – więc każdy może użyć:
https://github.com/chipmunk-sm/HexEditor

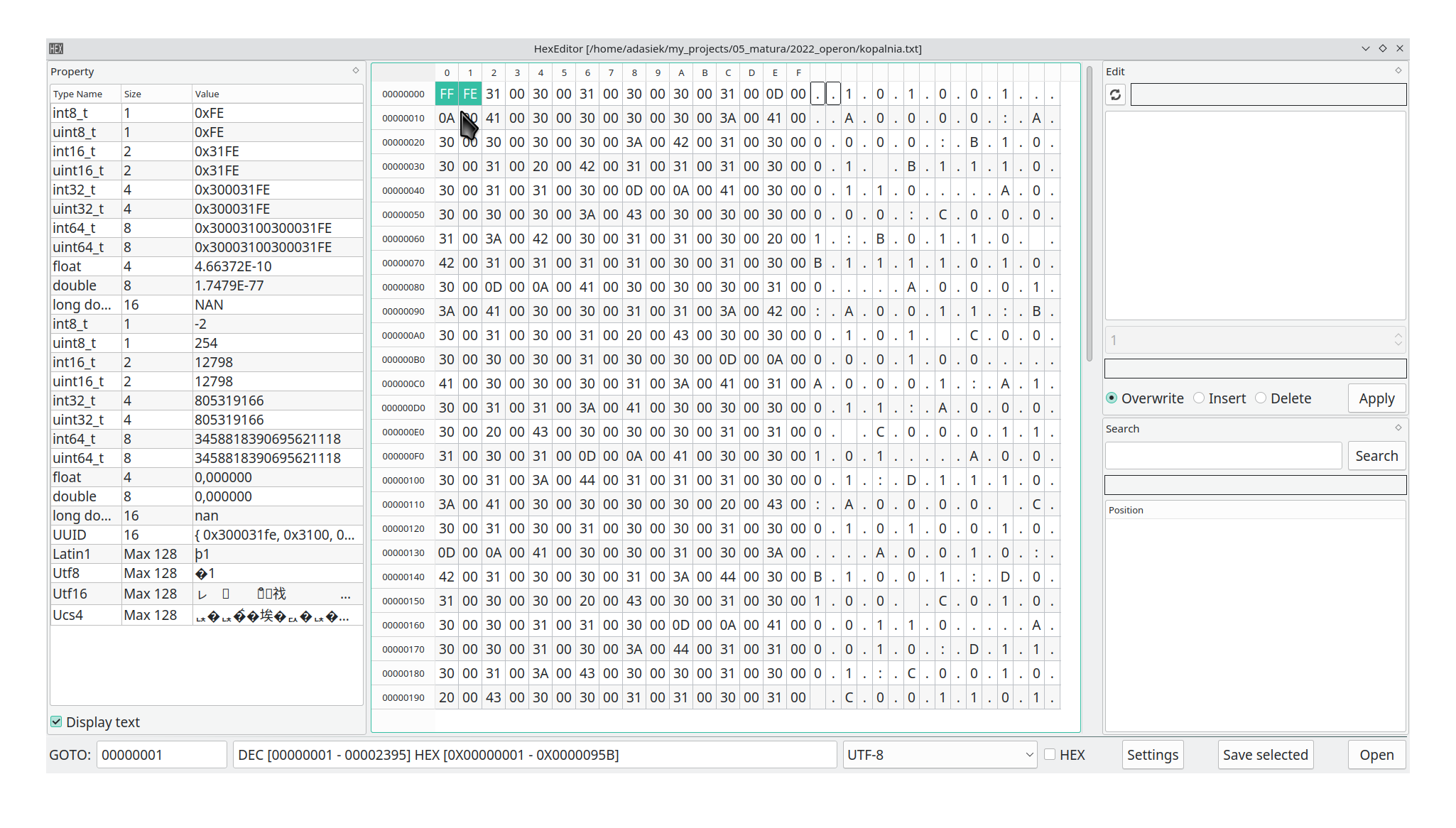
Widzimy dziwne 2 bajty na początku pliku – próba wczytania z wykorzystaniem Pythona kończy się błędem…

Zatem kasuję te 2 bajty i próbuję wczytać ponownie, ustawiając nawet kodowanie na UTF-8 – wtedy jednak widzę, że w środku plik jest bardzo dziwny…
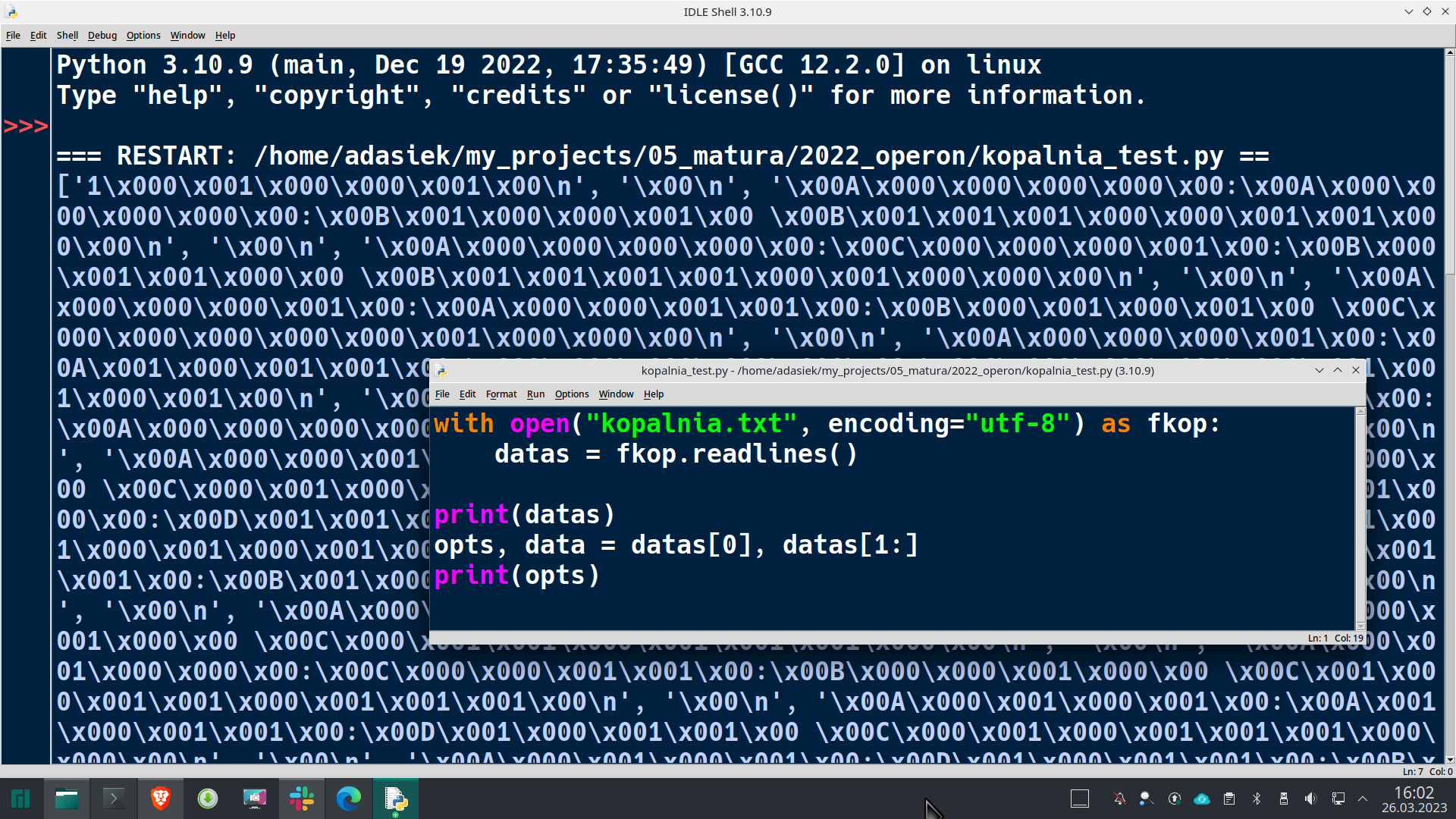
Zatem na razie dalej nie sprawdzam, czekam, aż sprawdzę, co Operon wystawia na swojej stronie internetowej… a więc cdn…
Teraz ciąg dalszy… Szybkie pytanie na grupie Facebook… i nieoceniony kolega Andrzej Dyrek podpowiada:
Oczywiście, zmiana kodowania przy otwarciu pliku pomaga w 100% 😉
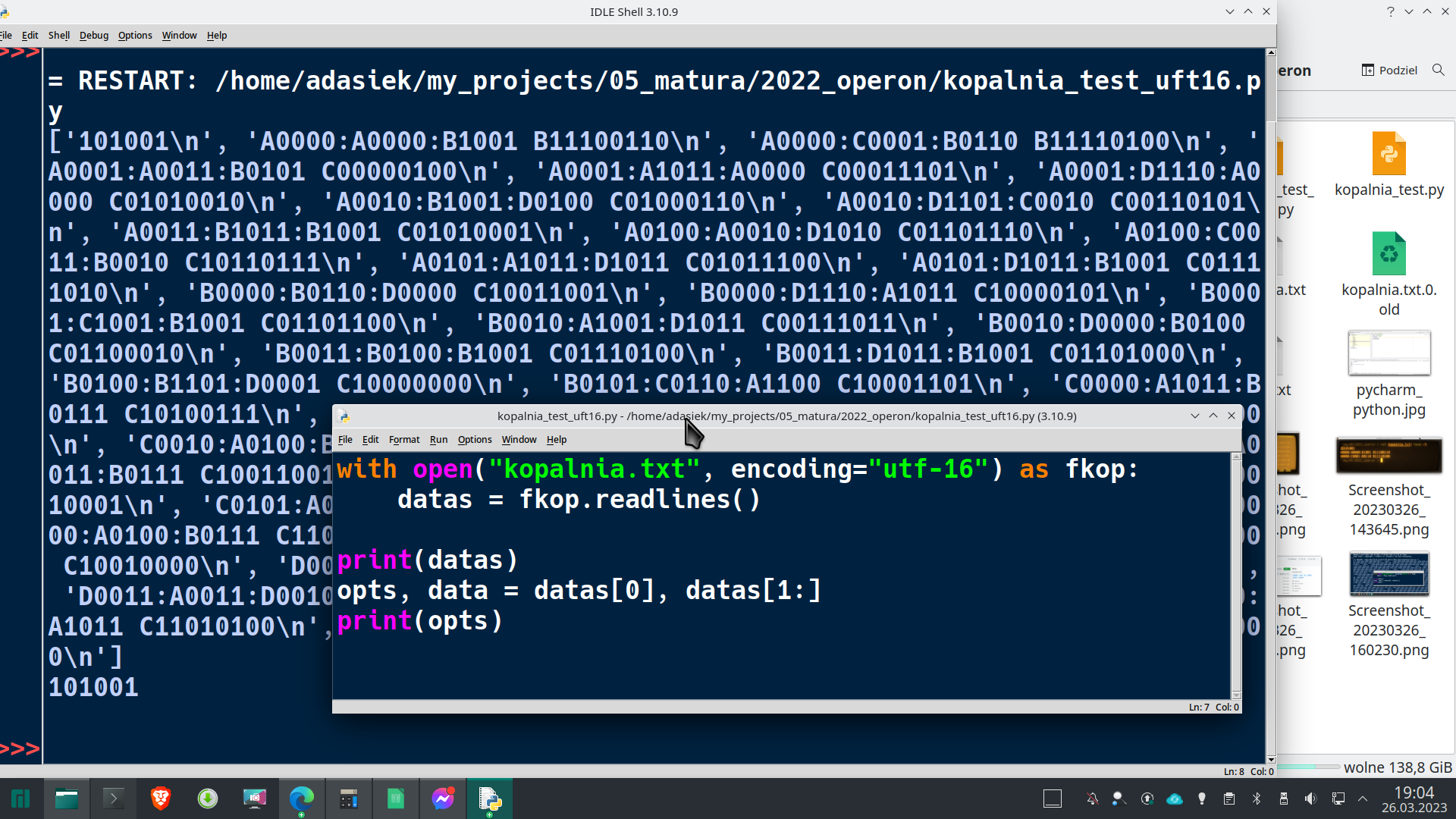
Zatem możemy przygotować kod, który pozwoli nam oczyścić dane wejściowe i przygotować je do dalszej obróbki.

with open("kopalnia.txt", encoding="utf-16") as fkop:
datas_file = fkop.readlines()
opts, datas = datas_file[0].strip(), datas_file[1:]
print(f"The opts from file: {opts}")
print()
print("And head of rest of datas...:")
for idx, row in enumerate(datas[:4]):
print(f"Row number: {idx} - value: {row.strip()}")
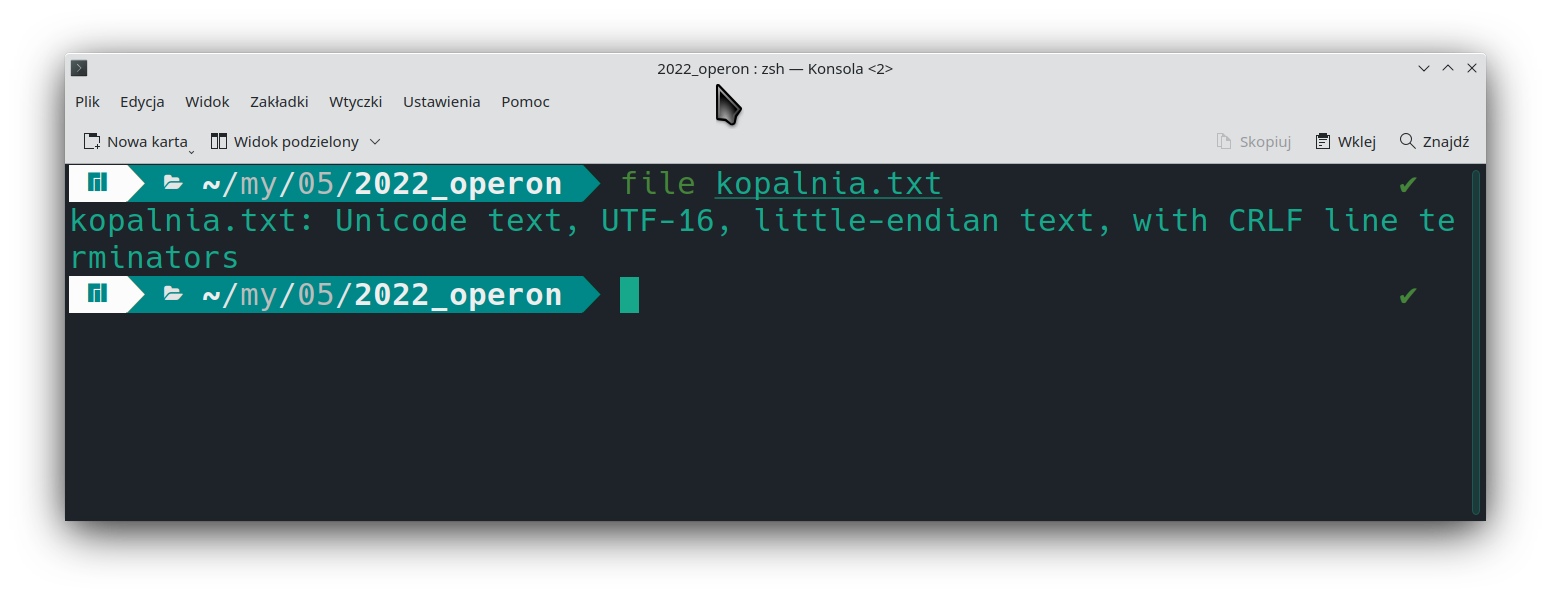
Drobny edit: nie wiem, jak w Windows, ale w Linuksie mam świetne narzędzie pokazujące kodowanie pliku – aż się dziwię, że nie sprawdziłem od razu….
Comments are closed.